企業リリース Powered by PR TIMES
PR TIMESが提供するプレスリリースをそのまま掲載しています。内容に関する質問 は直接発表元にお問い合わせください。また、リリースの掲載については、PR TIMESまでお問い合わせください。
(2021/12/2)
カテゴリ:商品サービス
リリース発行企業:NVIDIA

最新の MLPerf ベンチマークで、Dell、Inspur、Microsoft Azure、Supermicro が NVIDIA AI を使用して AI モデルのトレーニング速度の新記録を樹立

Dell Technologies、Inspur、SupermicroなどのNVIDIAパートナーが、12月1日 (太平洋時間) に発表された MLPerf training 1.1 において、NVIDIA AIを用いてAI モデルのトレーニング速度の新記録を新たに樹立しました。その中には、MLPerfベンチマーク初登場の Azureも含まれています。

NVIDIA のプラットフォームは、MLPerf training 1.1 の結果の中で、8 種類の一般的なワークロードのすべてにおいて新記録を打ち立てています。
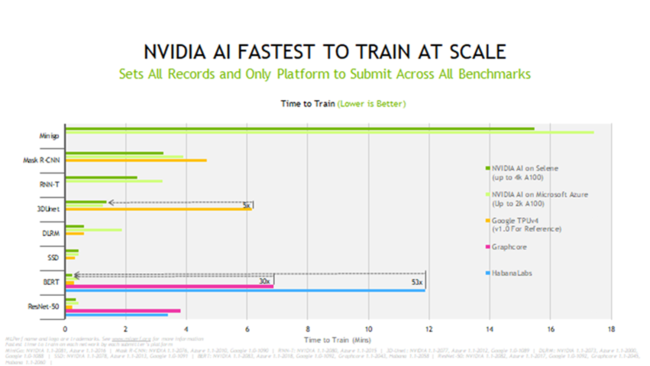
図:NVIDIA AI はMLPerfの最新ラウンドですべてのモデルを最速でトレーニングしました。
NVIDIA A100 Tensor コア GPU は、正規化された 1 チップ当たりの性能でトップを獲得しました。NVIDIA InfiniBand ネットワークとソフトウェア スタックでスケーリングし、モジュール式の NVIDIA DGX SuperPOD をベースにした NVIDIA の社内 AI スーパーコンピューターである Selene で最速のトレーニング時間を達成しました。
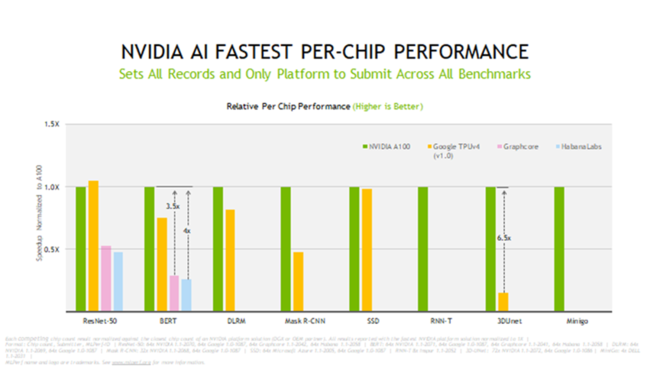
図:NVIDIA A100 GPU は、MLPerf 1.1 テストの全 8 項目で 1 チップ当たりのトレーニング性能においてトップを獲得しました。
クラウドがトップに躍り出る
最新結果によると、AI モデルのトレーニングに関しては Azure の NDm A100 v4 インスタンスが最速で、最新ラウンドではすべてのテストを実行し、2,048 基の A100 GPU までスケールアップしました。
Azure は、単に優れた性能を記録しただけでなく、その優れた性能を全米 6 地域で誰でもすぐに利用できます。
AI のトレーニングは、大規模なコンピューターを必要とする大きな仕事です。そして、NVIDIA はユーザーがそれぞれ選んだサービスまたはシステムを利用して記録的な速度でモデルをトレーニングできるようにしたいと考えています。
だからこそ、クラウド サービス、コロケーション サービス、企業、科学計算センター向けの製品でも NVIDIA AI を利用できるようにしています。
サーバー メーカーが実力を誇示
OEM の中では、Inspur が 8-way構成のNF5688MB システムと液冷式の NF5488A5 システムで、シングル ノード性能の項目で最多の新記録を打ち立てました。一方、Dell と Supermicro は 4-way 構成の A100 GPU システムで新記録を樹立しました。
今回のラウンドでは、合計 10 社の NVIDIA パートナーが結果を提出しました。内訳は OEM が 8 社、クラウドサービス プロバイダーが 2 社で、全体の 90% 以上を占めました。
NVIDIA のエコシステムが MLPerf のトレーニング テストでトップ スコアを記録したのは、今回で 5 度目となります。
NVIDIA のパートナーが MLPerf に取り組んでいるのは、MLPerf がAI トレーニングおよび推論に関する唯一の同業者からの審査がある業界標準のベンチマークであることを知っているからです。MLPerf は、顧客が AI プラットフォームや AI ベンダーを評価する貴重な手段です。
高速性が認証されたサーバー
Baidu PaddlePaddle、Dell Technologies、富士通、GIGABYTE、Hewlett Packard Enterprise、Inspur、Lenovo、Supermicro は、ローカルのデータセンターで、シングル ノードとマルチ ノードの両方でジョブを実行して結果を提出しました。
NVIDIA のほぼすべての OEM パートナーは、アクセラレーテッド コンピューティングを必要とするエンタープライズ顧客のために NVIDIA によって認証されたサーバーである NVIDIA-Certified Systems でテストを行いました。
提出された幅広いカテゴリの結果は、あらゆる規模の企業に最適なソリューションを提供する NVIDIA プラットフォームの多様性と成熟度を物語っています。
高速かつ柔軟
NVIDIA AI は、すべてのベンチマークとユース ケースで提出に使用された唯一のプラットフォームでした。このことから、NVIDIA AI が高い性能だけでなく汎用性も備えていることは明らかです。高速かつ柔軟なシステムは、お客様の業務の迅速化に必要な生産性向上をもたらします。
このトレーニング ベンチマークは、コンピューター ビジョン、自然言語処理、レコメンダー システム、強化学習など、現在最も一般的な 8 種類の AI ワークロードとシナリオを網羅しています。
MLPerf のテストは透明性と客観性が確保されているため、ユーザーはその結果を購入意思決定のための情報として頼りにすることができます。2018 年 5 月に設立されたこの業界ベンチマーキング団体は、Alibaba、Arm、Google、Intel、NVIDIA をはじめとする業界大手企業数十社によって支えられています。
3 年で 20 倍の高速化
数字を振り返ってみると、NVIDIA A100 GPU はこの 18 カ月だけで 5 倍以上のパフォーマンス向上を果たしたことになります。これは、近年の取り組みの中で最も大きな成果であるソフトウェアの継続的改善のおかげです。
NVIDIA のパフォーマンスは、MLPerf テストが登場した 3 年前から 20 倍以上向上しています。この大幅な高速化は、GPU からネットワーク、システム、ソフトウェアまでのフルスタックのソリューション全般にわたる進歩の結果です。
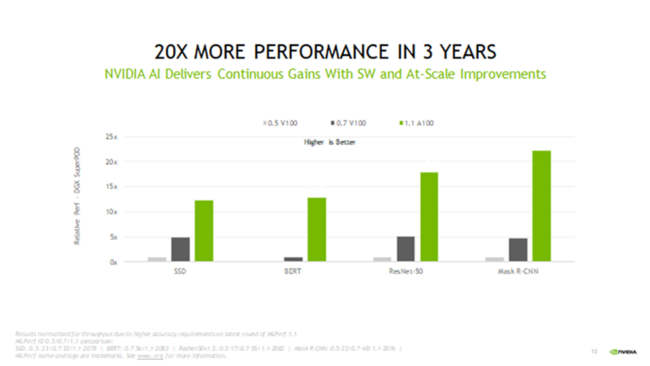
図:NVIDIA AI は 3 年で 20 倍以上の高速化を実現しています。
ソフトウェアの継続的改善
最新の進歩は、数々のソフトウェア改善によるものです。
例えば、医用画像に関する 3D-UNet ベンチマークでは、新しいクラスのメモリ コピー命令を使用することで 2.5 倍の高速化を達成しました。
GPU は並列処理向けに微修正可能であり、そのおかげで物体検出に関する Mask R-CNN テストで 10%、レコメンダー システムで 27% の高速化が実現しました。独立した命令をオーバーラップさせただけですが、これは、多数の GPU で実行されるジョブには特に有効な手法です。
また、ホスト CPU との通信を最小限に抑えるために、CUDA Graphs の使用を拡大しました。その結果、画像分類に関する ResNet-50 ベンチマークで 6% のパフォーマンス向上につながりました。
さらに、GPU 間の通信を最適化するライブラリである NCCL に関して、新たな 2 つの手法を実装した結果、BERT などの大規模言語モデルで 5% の高速化が実現しました。
誰でも活用可能な、NVIDIA の取り組みの成果
NVIDIA が今回使用したソフトウェアはすべて、MLPerf リポジトリから入手可能です。つまり、誰でも世界最高レベルの結果が得られるということです。上記の最適化は、GPU アプリケーションのソフトウェア ハブである NGC カタログから入手可能なコンテナに継続的に組み込まれています。
これは、最新の業界ベンチマークでその力が実証されたフルスタック プラットフォームの一部であり、また、プラットフォームは実際の AI ジョブに取り組むパートナー各社から提供されています。
企業プレスリリース詳細へ
PRTIMESトップへ
※ ニュースリリースに記載された製品の価格、仕様、サービス内容などは発表日現在のものです。その後予告なしに変更されることがありますので、あらかじめご了承下さい。